Regionalakzente in Deutschland

Worum geht es hier?
Nur wenige Merkmale sagen so viel über einen Menschen aus wie seine Sprache. Auf diesen Seiten widmen wir uns der regionalen Herkunft von Personen aus ganz Deutschland, deren Sprachgebrauch in einem groß angelegten Projekt (dem sog. REDE-Projekt) eingehender analysiert wurde. Im Mittelpunkt stehen dabei nicht die Dialekte, sondern die regionalen Akzente. Gemeint sind Sprechweisen, mit denen z. B. bei formalen Anlässen auf die Schrift- oder Standardsprache abgezielt wird, Dialekte also vermieden werden. Was in solchen Äußerungen noch an Regionalität erkennbar ist, ist der Gegenstand auf dieser Seite, denn: Wer spricht, äußert seine Herkunft.
Wir beschränken uns hier auf einige ausgewählte Aspekte. Dabei starten wir bei einem traditionellen Gliederungsansatz des Sprachraums. Über eine Zusammenführung unserer Daten erzielen wir darüber hinaus eine neue, für die Regionalakzente angemessene Raumbewertung.
Einen ersten Einblick zu den ausgewerteten Daten und Analysebeispielen erhält man in dem Beitrag “Regionalakzente in Deutschland” von Salome Lipfert. Zusätzlich gibt das Video-Tutorial von Dennis Beitel einen hilfreichen Überblick zum Aufbau der Plattform und eine Zusammenschau der wichtigsten Inhalte.
Projekt
Das Projekt Regionalakzente in Deutschland ist Teil des Akademieprojekts REDE. Es handelt sich um eine Ergebnispräsentation, die sich den an der Standardsprache orientierten Sprechweisen widmet. Als Gewährspersonen wurden neben (ehemals) manuell tätigen Sprechern der älteren Generation Polizeibeamte der mittleren Generation ausgewählt, die während der Jahre 2008 und 2014 in der gesamten Bundesrepublik Deutschland direkt vor Ort befragt wurden.
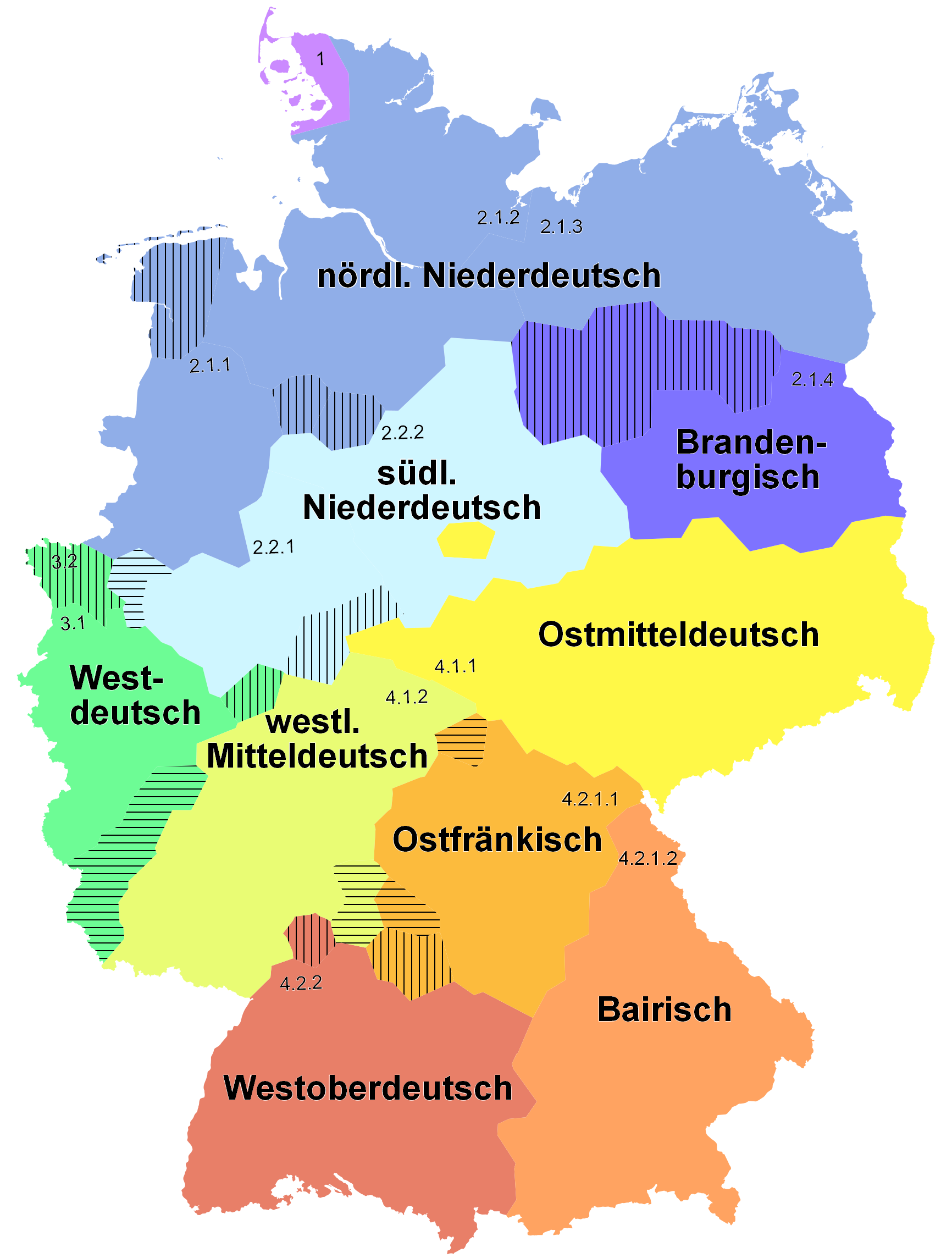
Auf diesen Seiten sind ausgewählte Ergebnisse zusammengetragen. Die Gliederung ist grundsätzlich an den bekannten Sprachräumen des Deutschen orientiert. Diesem Top-Down-Ansatz steht ein Bottom-Up-Ansatz zur Seite, der die aus den Daten ableitbaren räumlichen Muster beschreibt. Die Darstellung der Gewährspersonen erfolgt über alle Sprachräume hinweg. Zudem werden übergeordnete Ergebnisse in einzelnen Überblickskapiteln zusammengetragen.
Weitere Informationen zu den Regionalakzenten des Deutschen sind in einem auf diese Sprechlage ausgerichteten Projektteil zu finden. Ein Überblick in diesen Bereich findet sich hier.
Erhebung der Daten
Die Datenerhebung erfolgte durch professionell geschulte Personen in mehreren Erhebungsschritten. Für den hier präsentierten Projektteil werden die Daten einer Vorleseaufgabe (gelesen wurde die Fabel vom Nordwind und der Sonne) und einer Übersetzungsaufgabe ausgewertet. Bei der Übersetzungsaufgabe galt es, dialektal präsentierte Wenkersätze in die intendierte Standardsprache zu übersetzen.
Regionen
Folgende Regionen wurden für die Analyse ausgewählt. Ein Überblick über die Auswahl der Sprecher findet sich hier
Download
Raumübergreifende
Variantentabelle als Excel-Datei
Raumübergreifende
Variantentabelle als csv-Datei
REDE
| 2023
![]()
![]()
Lizensiert unter
Creative Common
Attribution 4.0 International (CC BY 4.0)

Kontakt
|
Impressum