Aggregation der Daten
1 Hintergrund
Ein Zugang zur Beschreibung der Regionalakzente in den Regionen ist die Analyse sprachlicher Realisierungen in den bekannten Sprachregionen des Deutschen. So lässt sich z. B. ermessen, wie die sprachlichen Realisierungen in einer an der Hochsprache orientierten Sprechlage im Ostfränkischen ausfallen. Dieser Zugang ist auf diesen Seiten mehrfach umgesetzt.
Ein anderer Zugang liegt darin, nicht die sprachlichen Realisierungen vordefinierter Räume anzuschauen, sondern umgekehrt aus dem Vorhandensein bestimmter sprachlicher Realisierungen auf zusammenhängende Sprachregionen zu schließen. Ein solcher Bottom-up-Ansatz lässt sich mit dem vorhandenen Material ebenfalls umsetzen. Das Ergebnis ist auf dieser Seite zu finden.
2 Vorgehen
Für eine raumvergleichende Analyse wurden in einem ersten Schritt die phonetischen Notationen der Nordwind-und-Sonne-Texte aller verfügbaren REDE-Gewährspersonen ausgewählt. Diese im Projekt erstellten Notationen wurden untereinander verglichen und auf Ähnlichkeit geprüft. Hierfür wurde eine n-gram-Analyse durchgeführt, bei der in einem Analysefenster immer drei Laute über die Orte hinweg verglichen werden. Die Differenz der Orte wird in einer Tabelle abgelegt, anschließend wandert das Fenster einen Laut weiter und erschließt die nächsten drei Laute usw.
Aus diesem Vorgehen ergibt sich eine Ähnlichkeitsmatrix der Orte. Mit einem fusionierenden Verfahren können anschließend auf Grundlage sämtlicher Daten solche Regionen definiert werden, deren Orte maximal ähnlich sind.
3 Räumliche Verbreitung der Regionalakzente
Das Ergebnis zeigt die folgende Grafik. Von wenigen Ausnahmen abgesehen, ergibt sich ein sehr deutliches Bild. Dargestellt sind die in der Analyse sich ergebenden hierarchischen Cluster (Ward-Algorithmus). Das erste Cluster (Clst_1) zeigt die räumliche Verbreitung der in der Analyse berücksichtigten Orte an. Auf der nächsten Hierarchiestufe ergibt sich eine Zweiteilung des Raumes, der das Oberdeutsche, aber auch das Ostmitteldeutsche sowie das Brandenburgische ausgliedert (Clst_2). Das sind nach Ausweis der REDE-Daten die Regionen, deren Vorlesesprache durch einen etwas stärkeren Regionalakzent auffallen. Es folgen auf den nächsten Hierarchiestufen das Bairische (Clst_3) und das Westoberdeutsche bzw. das Ostdeutsche und Brandenburgische (Clst_4). Sodann tritt das Westmitteldeutsche einschließlich dem Ostfränkischen hervor, womit zugleich ein norddeutscher Regionalakzent separiert wird (Clst_5). Schließlich wird der westdeutsche Raum als eigenes Cluster sichbar (Clst_6).
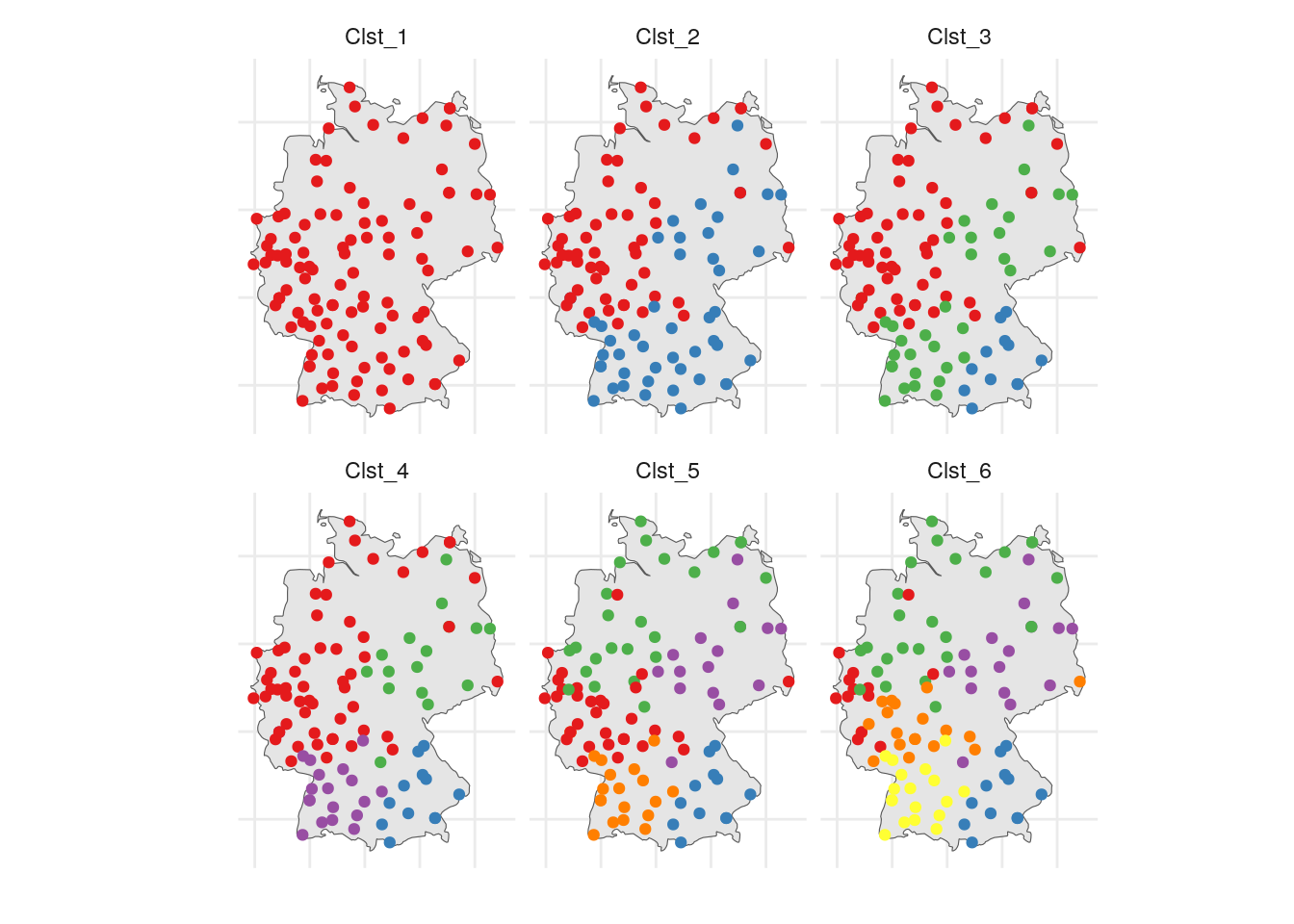
Iterative Clusterung der Regionalakzente in Deutschland (nach Ausweis der REDE-Daten)
Fasst man die Darstellung abschließend zusammen lässt sich eine
hohe Deckung mit den bekannten Spracharealen erkennen; Top-Down-
und Bottom-Up-Ansatz führen also zu vergleichbaren Ergebnissen,
sieht man einmal von einzelnen Ausreißern ab, die auf individuelle
Unterschiede zurückzuführen sind und zugleich auf die trotz aller
Regionalität doch sehr große sprachliche Ähnlichkeit der
Sprecheräußerungen hindeuten. Eine signifikante Ausnahme bildet mit
Blick auf die traditionellen Sprachräume das Ostfränkische, das sich aus
dem oberdeutschen Dialektverband löst.

4 Kontrast mit einem Nachrichtensprecher
Bei der Betrachtung der regionalen Unterschiedlichkeit stellt sich die Frage, wie sich das in den Regionen erhobene Sprechen zur normierten bzw. kodifizierten Standardsprache verhält. Eine Antwort lässt sich durch den Vergleich mit professionellen, d. h. phonetisch geschulten Sprecherinnen und Sprechern gewinnen. Die folgende Grafik zeigt einen solchen Vergleich mit einem Nachrichtensprecher der ARD Tagesschau (Jan Hofer). Dabei zeigt sich eine relativ einheitliche Distanz über die nord- und westmitteldeutschen Regionen hinweg mit zugleich deutlicher Unterschiedlichkeit im oberdeutschen und im ostmitteldeutschen Raum.
Besonders interessant ist jedoch die Verdichtung der höchsten Werte im westdeutschen Gebiet. Hier ist mit dem nördlichen roten Punkt (also der höchsten Ähnlichkeit der Regionalakzente zur Aussprache von Jan Hofer) der Ortspunkt Coesfeld angesprochen. Jan Hofer stammt aus der Gegend um Wesel. Unter den REDE-Erhebungspunkten ist Coesfeld der hierzu nächstgelegene Ort mit einer Distanz von ca. 60 km. Die Analyse hat damit die Heimatregion des Nachrichtensprechers getroffen (= westlichster Teil der Hierarchiestufe 2). In der Zusammenführung der Regionalakzente ist es damit gelungen, die regionale Prägung selbst professioneller Sprecherinnen und Sprecher regional einzuordnen.

REDE
| 2023
![]()
![]()
Lizensiert unter
Creative Common
Attribution 4.0 International (CC BY 4.0)

Kontakt
|
Impressum